Paper arXiv Code Demo #1 Demo #2
Geoffrey Hinton, Oriol Vinyals, and Jeffrey Dean. Distilling the Knowledge in a Neural Network. NIPS Deep Learning and Representation Learning Workshop 2015. [LINK]
We study the problem of creating a character model that can be controlled in real time from a single image of an anime character. A solution would greatly reduce the cost of creating avatars, computer games, and other interactive applications.
Talking Head Anime 3 (THA3) is an open source project that attempts to directly address the problem. It takes as input (1) an image of an anime character's upper body and (2) a $45$-dimensional pose vector and outputs a new image of the same character taking the specified pose. The range of possible movements is expressive enough for personal avatars and certain types of game characters.
THA3's main limitation is its speed. It can achieve interactive frame rates ($\approx$ 20 FPS) only if it is run on a very powerful GPU (Nvidia Titan RTX or better). Based on the insight that avatars and game characters do not need to change their appearance every so often, we propose a technique to distill the system into a small student neural network (< 2 MB) specific to a particular character. The student model can generate $512\times512$ animation frames in real time ($\geq$ 30 FPS) using consumer gaming GPUs while preserving the image quality of the teacher model. For the first time, our technique makes the whole system practical for real-time applications.
The THA systems, including the 4th version that we propose in this paper, is overly capable. At any time, we can change the chracter image and animate it immediately. However, our target use cases—virtual YouTubers (VTubers) and game characters—does not change their appearance every second and every minute to warrant this functionality. By creating neural networks that are specialized to a specific character image, we may obtain faster models that work under real-time constraints.
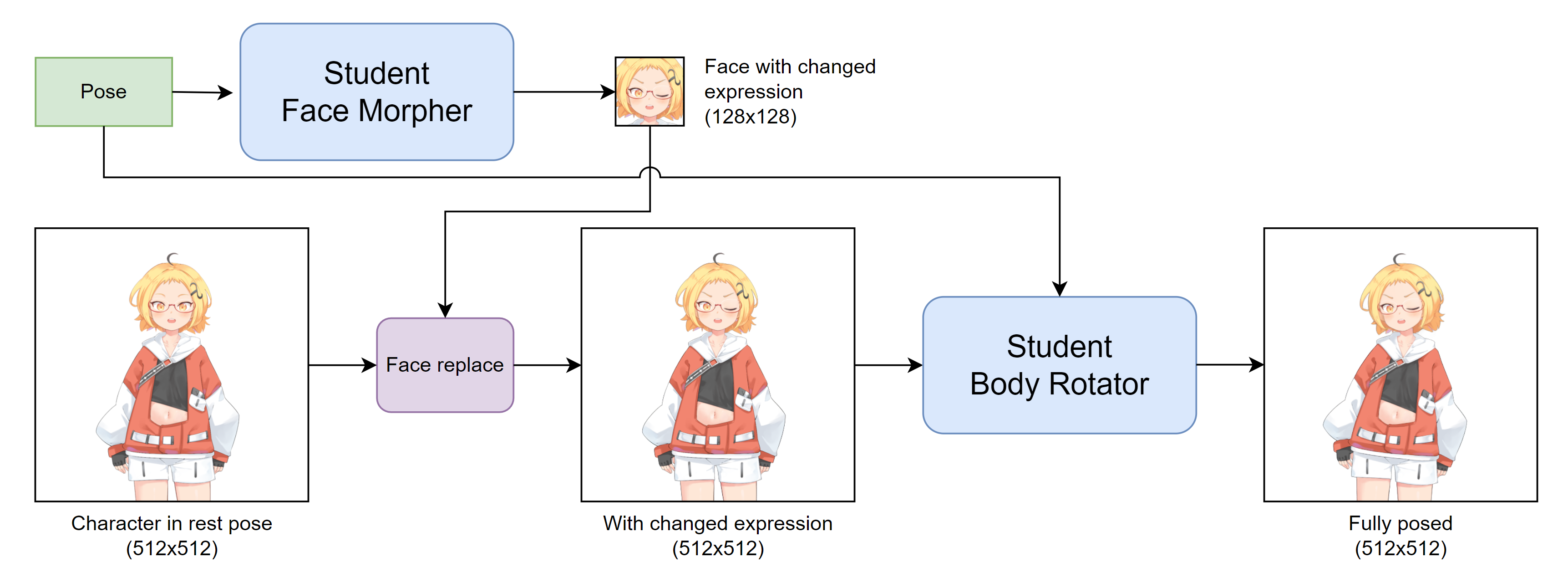
The faster models in question are created by knowledge distillation, the practice of training a machine learning model (the student) to mimic the behavior of another model (the teacher). In our case, the teacher model is the improved THA system. The student is a collection of two neural networks. The face morpher modifies the character's facial expression, and the body rotator rotates the face and the toros.
Architecture-wise, the face morpher is a SInusoidal REpresentation Network (SIREN) [Sitzmann et al. 2020]. The body morpher is also a SIREN but with two modifications. First, it generates images in a multi-resolution, starting with 128$\times$128, then 256$\times$256, and then 512$\times$512. This modification makes it fast enough to achieve real-time frame rates. Second, it uses image processing operations such as warping and alpha blending. This modification makes it preserve the details of the input character image better.
Vincent Sitzmann, Julien N. P. Martel, Alexander Bergman, David B. Lindell, and Gordon Wetzstein. Implicit Neural Representations with Periodic Activation Functions. NeurIPS 2020. [LINK]

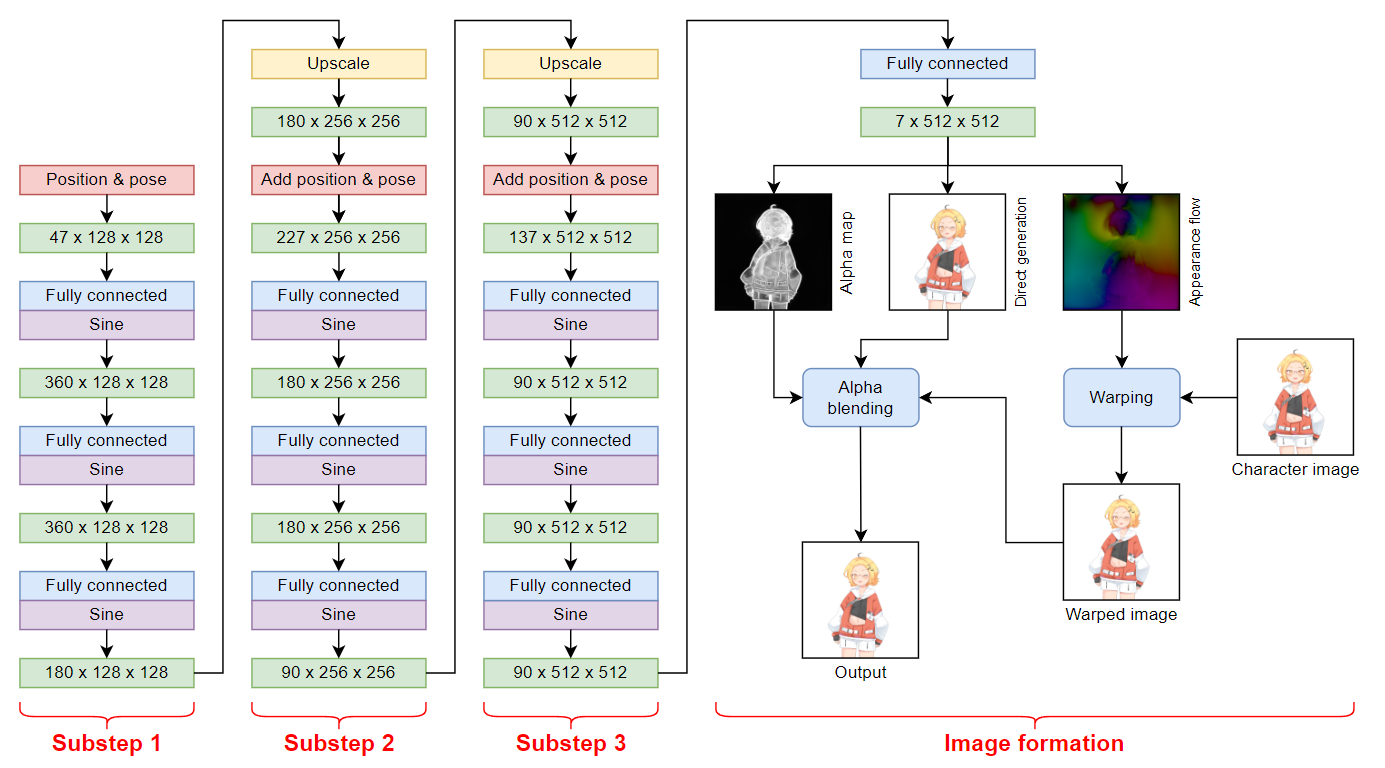
Details such as how to train the student model and how it performs against the teacher are available in the paper.
We provide two demo web applications.
The demos are best run on a computer with a dedicated gaming GPU. We were able to get real-time frame rates with an Nvidia GeForce 1080 Ti.
The supplementary material for the paper is available in this web page.
To create the demos, we use illustrations by 3rd party creators.
We use three illustrations from 東北ずん子・ずんだもんプロジェクト by SSS LLC. They are:
We use 7 illustrations by Mikatsuki Arpeggio (三日月アルペジオ). They are:
We thank the creators for generously providing the illustrations for us to build upon.
While the neural networks are developed with PyTorch, the web demos use TensorFlow.js with custom units we develop ourselve. We use Mediapipe FaceLandmarker to perform blendshape parameter estimation from webcam feed.
Project Fuji